Subspace clustering for the analysis of geo-referenced time series

Geo-referenced time series are data describing the time-changing behavior of one or more attributes at fixed locations and consistent time intervals [1]. For example, the weather stations located all around the world provide a vast amount of daily meteorological data containing various measurements such as temperature. Analysis of such huge datasets and exploring spatio-temporal patterns is a challenging task. Machine Learning (ML) has shown great improvement in the trade-off between speed and accuracy in time series analysis. ML has offered automatic or semi-automatic approaches for integrating all the sources of information, discovering the underlying relationships, and making predictions. Clustering is an ML technique to group data points with similar properties. It allows exploring hidden relationships between data points and gaining valuable insights about the spatio-temporal patterns within time series.
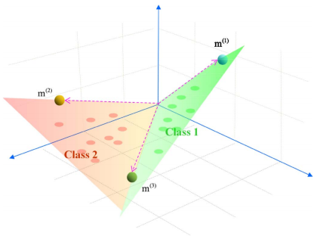
Selecting an appropriate clustering method remains to be a challenge, which is very important to achieve good results. Traditional clustering algorithms (e.g., K-means) normally use a specific distance measure to characterize the similarity between any two time series. They often assume data lie in a single subspace. However, considering the nature of time series that involves the three components, space, time, and attribute, the data points may be assumed to lie in a union of several low-dimensional subspaces. Particularly, this could be more relevant in high dimensional time series in which the number of time series is much larger than the length of each time series. Subspace clustering algorithms are advanced clustering techniques that explore the data to find multiple low dimensional subspaces and identify the data points that belong to each subspace [2-4]. For example, the sparse subspace clustering (SSC) algorithm constructs a similarity graph using the sparse coefficients, and groups data points using spectral clustering [2]. This study aims to explore the application of the SSC algorithm (or its modified versions e.g., [3]) for the analysis of geo-referenced time series and conduct a comparative study and evaluate the performance of this algorithm. A data set is available to map spring onset phenoregions over the conterminous 48 US states. This dataset can also be used to test the robustness of the proposed clustering method to deal with big geospatial data.
Exploring and implementing subspace clustering algorithms for the analysis of geo-referenced time series
- [1] Wu, X., Cheng, C., Zurita-Milla, R., & Song, C. (2020). An overview of clustering methods for geo-referenced time series: from one-way clustering to co-and tri-clustering. International Journal of Geographical Information Science , 1-27.
[2] Elhamifar, E., & Vidal, R. (2013). Sparse subspace clustering: Algorithm, theory, and applications. IEEE transactions on pattern analysis and machine intelligence, 35(11), 2765-2781.
[3] Rafiezadeh Shahi, K., Khodadadzadeh, M., Tusa, L., Ghamisi, P., Tolosana-Delgado, R., & Gloaguen, R. (2020). Hierarchical Sparse Subspace Clustering (HESSC): An Automatic Approach for Hyperspectral Image Analysis. Remote Sensing, 12(15), 2421.
[4] Khodadadzadeh, M., Contreras, C., Tusa, L., & Gloaguen, R. (2018, October). Subspace clustering algorithms for mineral mapping. In Image and Signal Processing for Remote Sensing XXIV (Vol. 10789, p. 107891V). International Society for Optics and Photonics.